Attention : l'utilisation d'un fichier tableur comme source de données est en cours de dépréciation, au profit de l'utilisation des fiches. Aussi, si vous devez créer maintenant une source de données, prévoyez directement une gestion de votre source de données à base de fiches.
Fichiers avec plusieurs colonnes
Nous avons vu comment fabriquer une source de donnée simple, mais il est possible d'avoir un fichier tableur avec de nombreuses colonnes. Pour l'exploiter il suffit d'ajouter des noms de clés pour les colonnes, au lieu d'avoir simplement :
id, text
On pourra avoir :
id, text, adresse, nom, prenom
Si le CSV est relié à un champ de formulaire ayant par exemple pour identifiant « valeur », {{form_var_valeur}} va contenir une cellule de la colonne « text » et les autres cellules pour cette même ligne seront disponibles dans les variables {{form_var_valeur_nom}}, {{form_var_valeur_prenom}} et {{form_var_valeur_adresse}} ; {{form_var_valeur_raw}} contiendra une cellule de la colonne « id ».
Interrogation directe
Filtres simples
En admettant que nous avons créé un connecteur CSV dont l'identifiant est « musees », le fichier est alors interrogeable directement en utilisant les URL ci dessous :
{{passerelle_url}}csvdatasource/musees/data
Retourne toutes les lignes du fichier.
{{passerelle_url}}csvdatasource/musees/data?q=abc
Retourne les lignes contenant « abc » (ou « ABC ») dans la colonne « text ».
Construction de requêtes
Lorsqu'on n'arrive pas à obtenir l'information désirée avec ce type d'interrogation directe, il est possible de construire des requêtes dont l'objectif est, en particulier, de pouvoir déplacer le focus sur une colonne particulière et de lui appliquer des traitements comme le filtrage, le dédoublonnage ou le tri.
Pour cela, lorsqu'on est sur la page d'accueil du connecteur, il faut cliquer sur « Nouvelle requête », lui donner un nom, une description et l'enregistrer.
Anatomie d'une requête
Les requêtes sont paramétrées à l'aide d'expressions Python, chaque champ de la requête accepte une liste d'expressions séparées par des sauts de ligne.
Les variables accessibles dans ces expressions sont nommées en fonction des noms de colonne définies dans le connecteur au fichier tableur. Si par exemple une colonne se nomme « adresse » vous pourrez utiliser la variable « adresse » dans vos expressions, elle contiendra la chaîne de caractère située dans la colonne « adresse ».
Une requête va permettre d'envoyer une valeur particulière pour un paramètre passé à l'URL de la requête. Si vous ajoutez un filtre (voir plus bas) commune == query['commune'] par exemple, vous pourrez d'ajouter ?commune=CASSIS à l'URL, pour obtenir uniquement les lignes du CSV pour lesquelles la valeur de la commune est « CASSIS ».
Si notre connecteur a pour identifiant liste-ecole, et notre requête d'exemple commune, les écoles de CASSIS seront accessibles grâces à l'URL :
{{passerelle_url}}csvdatasource/liste-ecole/query/commune/?commune=CASSIS
Attention, par défaut lorsqu'un filtre est construit, le paramètre devient obligatoire et s'il n'est pas envoyé dans l'URL, l'expression provoquera une erreur. Pour rendre un paramètre optionnel on utilisera la sous-expression « query.get('commune') » qui renverra une valeur nulle en cas d'absence de ce paramètre. On testera la présence d'un paramètre avec la sous expression « 'nom_du_parametre' in query ».
Paramétrage d'une requête
Les différents paramétrages sont :
- les filtrages : des expressions booléennes (Oui/Non) définissant si une ligne du tableau doit être conservée ou pas ;
- les tris : des expressions de type quelconque (numérique ou chaîne de caractère). Les lignes seront triées par l'ordre lexicographique de la valeur de ces expressions, c'est à dire que l'on va d'abord trier par la valeur de la première expression, puis, en cas d'égalité, par la valeur de la seconde expression (puis de la troisième, et ainsi de suite) ;
- les dédoublonnements : une liste d'expressions définissant une clé à une ou plusieurs valeurs, en cas d'égalité dans les clés, seule la première ligne du tableau ayant cette valeur de clé est conservée,
- les projections : les projections sont composées d'un nom puis d'une expression Python séparée par un caractère deux points (« : »), elles permettent de renommer, transformer et restreindre les valeurs d'origine du tableau.
Pour aider à la compréhension de ces différents paramètres nous allons partir de l'exemple d'une liste d'horaire pour un réseau de transport public. On supposera un fichier tabulé donnant les horaires, les lignes et les arrêts. Les horaires seront donnés sous la forme d'une chaîne de caractère à 4 chiffres comme « 0840 » facilitant ainsi les comparaisons.
| horaire | ligne | arret |
| 0840 | A | Avenue du Revestel |
| 0900 | A | Faculté |
| 0930 | A | Opéra |
| 0940 | A | Avenue du Revestel |
| 1000 | C | Les Goudes |
| 0940 | B | Rue du Château |
| 1000 | B | Hotel de ville |
Nous supposerons que le connecteur créé pour ce fichier se nomme transport, les requêtes que nous allons définir seront donc accessibles via : {{passerelle_url}}/csvdatasource/transport/nom-de-la-requête/
Dans un premier temps on souhaitera construire une requête renvoyant la liste des lignes. Pour cela on utilisera le dédoublonnement (pour ne pas avoir de répétition) mais aussi les projections pour obtenir des colonnes nommées « id » et « text » (obligatoires).
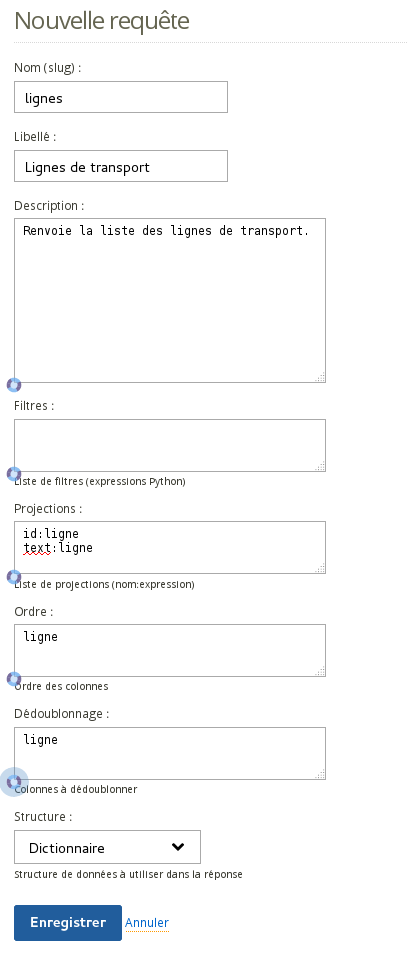
Cette requête renverra le document JSON suivant sur un GET à l'URL {{passerelle_url}}/csvdatasource/transport/query/lignes/ :
[
{ "id": "A", "text": "A" },
{ "id": "B", "text": "B" },
{ "id": "C", "text": "C"}
]
La prochaine requête que nous pourrions vouloir est la liste des arrêts pour une ligne donnée, dans l'ordre des horaires :
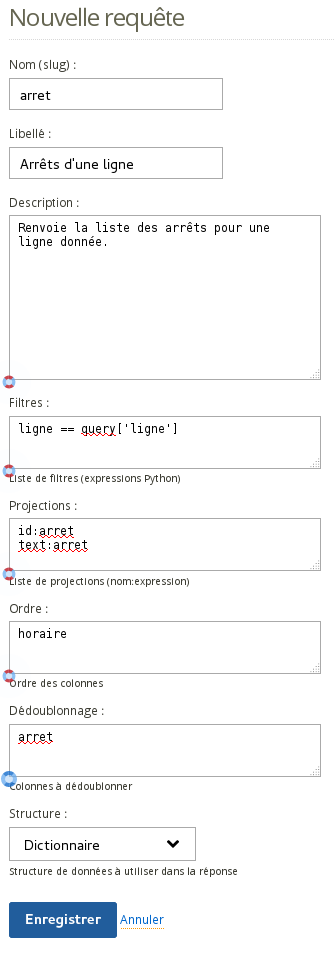
Cette requête renverra le document JSON suivant sur un GET à l'URL {{passerelle_url}}csvdatasource/transport/query/arret/?ligne=A :
[
{ "id": "Avenue du Revestel", "text": "Avenue du Revestel" },
{ "id": "Faculté", "text": "Faculté" },
{ "id": "Opéra", "text": "Opéra" }
]
Pour obtenir la liste des horaires pour un arrêt donné d'une ligne, on passera ligne et arrêt en paramètre, on filtrera selon ces deux paramètres avec :
ligne == query['ligne'] arret == query['arret']
on triera selon la colonne « horaire » et on projetera la même colonne « horaire » sous les noms « id » et « text ».
Structure du format retour
Par défaut les requêtes retournent une liste de dictionnaires (ou tableaux JSON) dans un document JSON ayant cette forme :
{
"err": 0,
"data": [
{..ŕesultat 1..},
{..résultat 2..}
...
]
}
Cette structure/format est nommé « Dictionnaire ».
Mais d'autres formats sont possibles :
- tableau : le champ « data » contient un tableau dont chaque ligne est un tableau des valeurs ordonnées en fonction des projections définies ou des noms des colonnes,
- tuples : le champ « data » contient un tableau dont chaque ligne est un tableau de paires dont le premier élément est le nom d'une colonne ou d'une projection et le second élément sa valeur, ex.: [ ["id", 1], ["text": "valeur 1"] ],
- une seule ligne : ce format suppose que la requête ne peut renvoyer qu'une seule ligne, dans ce cas le dictionnaire de cette ligne est directement renvoyé dans le champ « data »; si la condition n'est pas remplie une erreur sera levée,
- une seule valeur : ce format suppose qu'en plus de ne renvoyer qu'une seule ligne, cette ligne contient une colonne unique, dans ce cas la valeur de la colonne sera renvoyée dans le champ « data »; si la condition n'est pas remplie une erreur sera levée.
Vous n'avez pas trouvé ce que vous cherchez ?
Une suggestion ? Écrivez-nous !
Dernière mise à jour le 24/07/2026 11:59